
One of the core impedance mismatches between k8s control planes and compute control planes is how disks are attached and the constraints thereon.
Why does it matter?

Whereas with VMs, adding a disk is a relatively rare day 2 operation, in a k8s environment, attaching a disk is part of restarting a pod that failed.
And how that fundamentally affects the availability of the application that runs in kubernetes.
Now I want to talk about another challenge.
To create a virtual disk via the CSI, you must interact with the infrastructure control plane.
Now the performance, availability, and location of the infrastructure control plane matter.
With Nutanix, you can configure the CSI system to communicate directly with the PE. When you do that, our CSI provider provisions a virtual disk, and the CSI interacts with the underlying PE control plane running on the kubelet. What’s important is that if the VM is running, then the PE control plane is accessible because an endpoint exists on the same physical host.
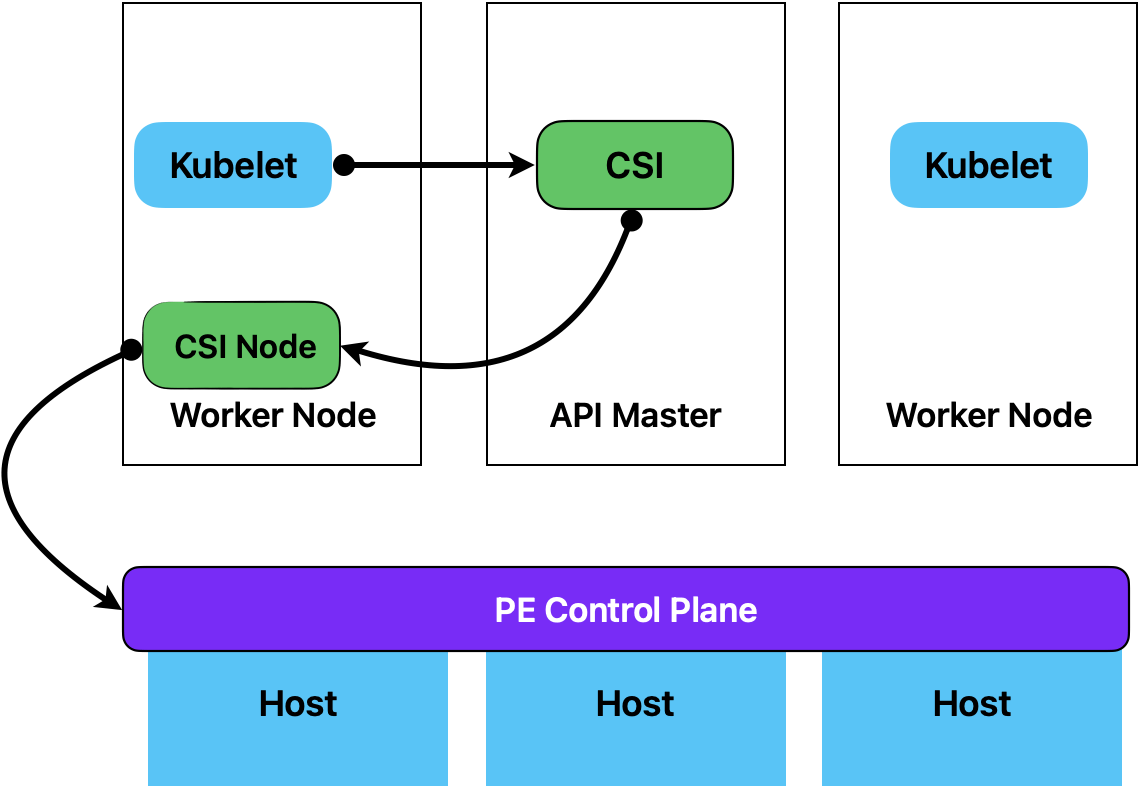
If you do not use the Nutanix CSI in PE mode, the CSI provider must communicate with the PC. This can lead to issues where the kubelet is unable to provision a disk because it depends on an external system.
The VCF 9.0 product documentation includes an excellent illustration of this architecture.

This leads to an availability mismatch, which adds complexity. The external control plane must be more available than any host that creates a pod. The network must be designed to support that level of availability. While this is achievable, it introduces additional tradeoffs.
What I like about the Nutanix platform is the choice it offers. And depending on the tradeoffs that matter for you, you can make different choices.





