
Using my agentic identity, I have been probing into the differences between VCF and Nutanix’s architecture.
And my agentic personality is very happy with the identity scheme that VCF 9.0 shipped, and it pointed out why it’s incomplete.
And then, as I looked into it more deeply, it was really a great example of how architectural differences make it easier for the Nutanix folks to deliver a better product faster.
So login and authz are related but different problems. Login determines who you are, and authorization determines if you can do something. Single Sign-On is a system that lets me log in once and authorize access across multiple applications.
The challenge with authorization is that, for security and control, it must be done where the entity exists.
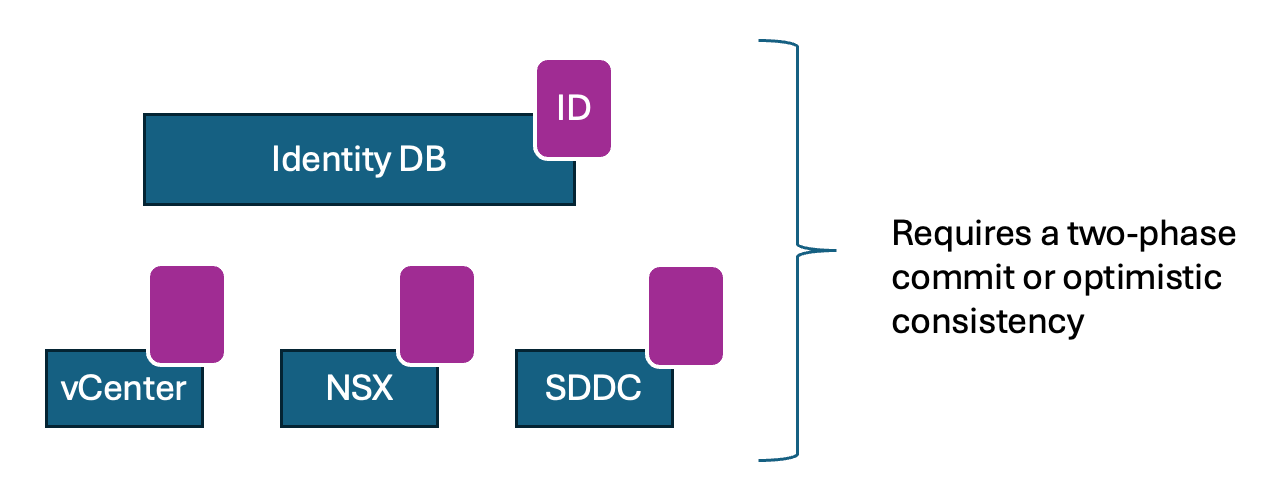
So what did the VCF folks do? They moved login into a new database at the VCF management domain level, and that was a decision I didn’t agree with because it impacts availability, but that’s a debate we can have endlessly.
But what about authorization? The VCF product has a problem: an entity, such as a VM and its host, exists in different product databases with different data.
NSX knows about hosts and stores certain values in its database. The SDDC manager maintains a database of hosts that stores critical information for each host and, of course, vCenter.
So if you want to authorize a user to complete a workflow (a set of API calls) that typically involves interacting with multiple products, such as SDDC manager, vCenter, etc., then all of those products have to be updated with the authorization.
And there is a lot of complexity involved in making that work. And I am sure that the VCF team did that work.
And then I compare it to what we had to do at Nutanix.
Since each entity and its complete state live in exactly one distributed database, you don’t have the problems of federated updates, partitions, errors, or scaling that VCF has.
So a much smaller team can deliver single sign-on.
And it’s why Nutanix, which has a much smaller team than VCF, can deliver a more robust and complete authorization and identity system than VCF.








