
I have been spending a lot of time on the next phase of system administration, agentic system administration. How can you use Agentic flows to manage infrastructure?
And Keith Townsend has put together an excellent mental model that I want to focus on. Not to critique it, but to ask: what is required of the infrastructure to provide what he calls the 2C reasoning layer?
My view on LLMs is that they are probabilistic theorem provers. If you can shrink the facts down narrowly enough, the theorem prover will probably know the right answer because the probability of you having a unique enough problem in practice is zero.
Where they fail is when the set of facts is too large, there are too many options, or the facts change mid-execution.
For anyone who has Claude, Codex, or Cursor, imagine having the systems try to update your code while someone else is simultaneously editing it. The results would be ugly.
There are three elements to facts:
- (1) They must be facts. Every path to the fact must produce the same fact.
- (2) The semantics of the facts must be encoded.
- (3) The policies of the facts must be encoded.
A natural, convenient, and reasonable way to get those facts is through an MCP server. But it’s more than just an MCP server that naively transforms the API set. Here are the layers I view as essential.
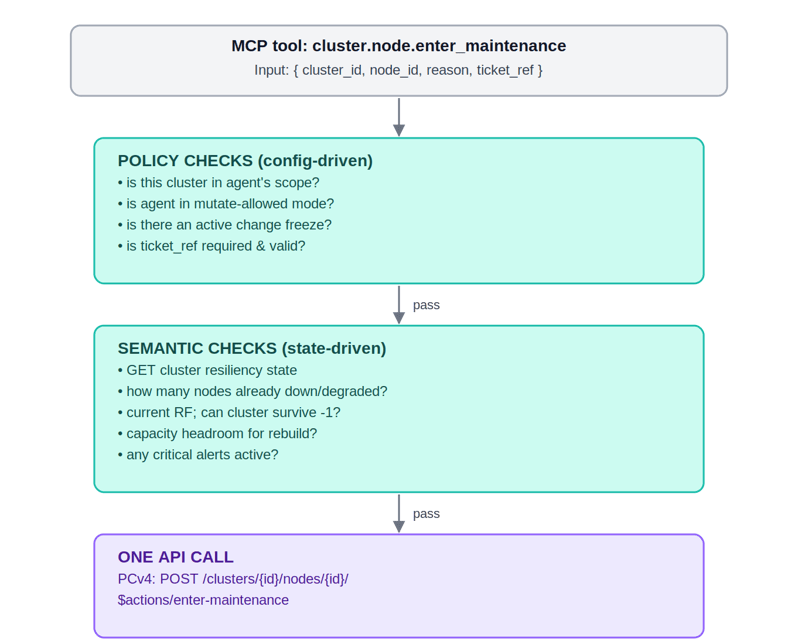
The semantic layer is useful when I am trying to power off a host. Powering off a host can be a fact, but the claim that the cluster may crash when you power off a host is semantics. And that semantics is deterministic. But if you don’t provide it, you are allowing the probabilistic theorem to infer that, and it may not.
The policy layer is what says, “You can power down a host on Tuesday.”
But both the policy and semantic layers need a deterministic ground-truth layer that provides a single view of the host’s state. And that the host’s state must remain the same regardless of how the API’s state is queried. And that any change in the host state is reflected everywhere.
If it’s not, then the semantic layer can’t know if the host can be shut down, the policy layer doesn’t know if the host is the one that can be shut down, and so the layer above the MCP can only guess, and when the consequences of guessing are a catastrophic layer, it all breaks.
Nutanix’s infrastructure is not an orchestration layer of sharded, incoherent state; instead, it is built on a single global transactional and resilient database that provides local autonomy and global consistency, serving as the foundational layer required by any 2C system.
To make my point, let’s look at Proxmox and OpenShift. Please note that any errors are mine, and if I got this wrong, I would love to correct it.
Let’s first look at OpenShift

This looks good until you see that last layer. The challenge is that, because of how K8S works, until the operation completes successfully, the system remains in an indeterminate state. So, although the kubernetes API says “the system is thus,” or rather the ‘desired state is thus,’ it can not guarantee when it says that the state hasn’t shifted.
Again, is the host down, or is it on its way to being down? The k8s layer doesn’t know. And so the MCP server has to either wait for the k8s layer to find out and then act, or reach around the k8s layer.
Worse, any operator can reverse a decision the MCP server made. So the MCP server is dealing with a state that can change behind its back, and that change can break the decisions that an agent sitting on top of the MCP server made.
From the agent’s perspective -> I saw facts, I made a decision, the decision failed. The problem is that the facts changed while the agent wasn’t looking. So it goes back and asks again, and gets different facts, so it does something different.
The probabilistic theorem prover is looking at a set of facts that are continuously changing
Now let’s look at Proxmox
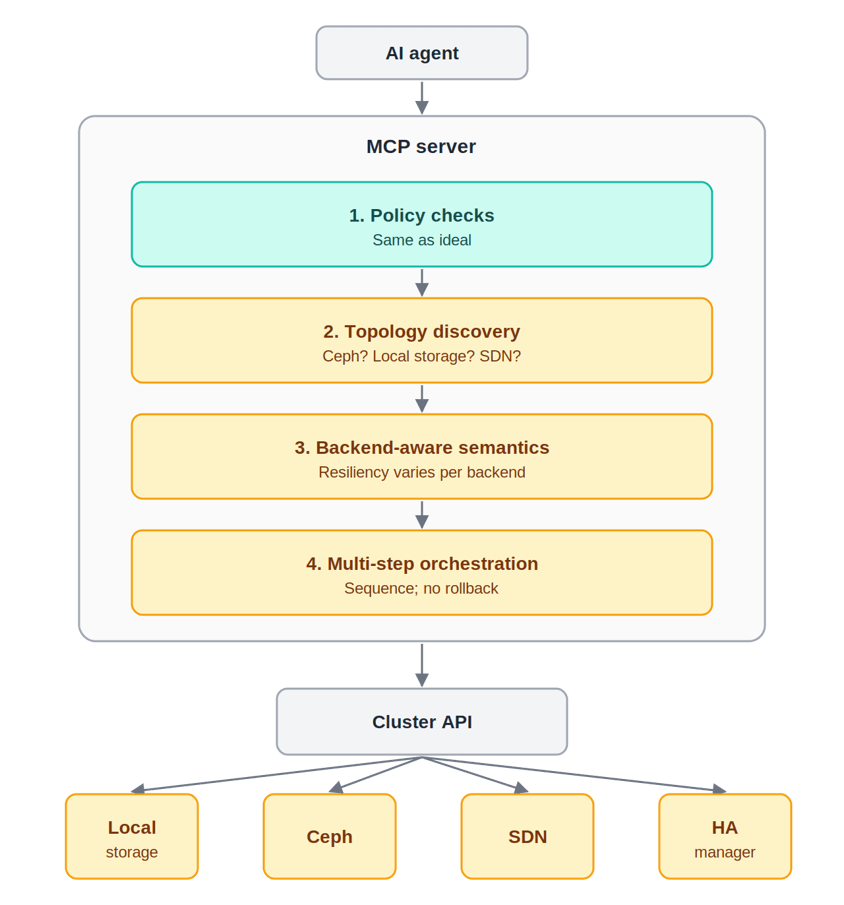
Again, the MPC server has control planes with overlapping state. It must figure out who to query and when, and orchestrate an operation that is not transactional. So from the agent’s perspective, the fact is malleable. And a malleable fact is destructive for a probabilistic theorem prover.
After the MCP server returns, the actual ground state is unknown.
So the agent is always wondering why the thing didn’t work. And the answer is because the facts changed. But then, the agent has to start again. And then it has to create a plan that can account for every possible change, or it has to give up.
Leave a Reply