OpenShift has adopted a radical proposal to move k8s beyond application orchestration into infrastructure orchestration.
Let me observe that k8s, as an orchestration layer, is a fabulous piece of technology, and it relies on a desired-state design pattern, where different controllers are asked to do something, and any errors are expected to be resolved out of band.
And my criticism is not of the desired state or of k8s, but of the assumption that it is the best or even desirable way to manage Infrastructure.
What is Infrastructure? Infrastructure should just work. When it fails, it should be obvious why and easy to correct.
For example, when I create a VM, I expect the VM to be created. If the VM creation requires updating the network infrastructure or changing the storage infrastructure, the operation completes with a specific error message indicating what failed, or with success.
With the desired state, the operation doesn’t complete; instead, the operator has to determine which part of the workflow is stalled and fix it until the next error occurs.
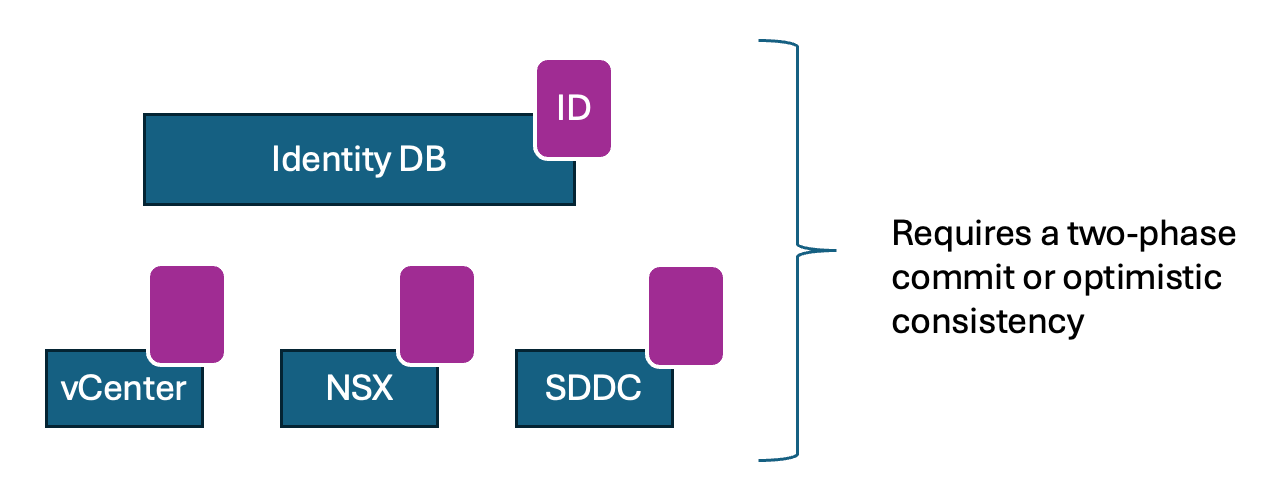
While at VMware, I assume the desired state is the only answer. And the reason is that the VMware SDDC is built from a series of stateful applications that share and overlap state. And the reality is that without digging into the underlying stateful service, it was impractical to categorize the error completely. With the ability to restore stateful services independently of each other and the lack of transactional services, errors could occur that required a human to intervene.
At Nutanix, I discovered, to my amusement, that the v3 APIs adopted the k8s style of desired-state management. And that, while using them, Nutanix engineers and customers found that the desired state got in the way of error propagation, making the system less usable.
And so Nutanix rejected them for imperative APIs and thus introduced the v4 APIs.
In short, Nutanix said that “Infrastructure either works as an operation or it doesn’t. And if it doesn’t, we should give you an immediate and clear error. We shouldn’t make it your problem to go debug the Infrastructure.”
To do that, you need a strictly consistent database that all infrastructure control planes use, a single entity model, and a stateless hypervisor and file system.
Without that, the OpenShift model is the only path forward.